Kontextfreie Sprachen
In Programmiersprachen benötigen wir Klammerstrukturen, und diese lassen sich mit regulären Grammatiken nicht realisieren. Die Art der zulässigen Regeln in Grammatiken muss erweitert werden.
| Definition: Kontextfreie Grammatik |
|
Eine Grammatik heißt kontextfrei oder umgebungsunabhängig, wenn jede Regel die Form (A -> w) mit Entscheidend ist, dass auf der linken Seite einer Regel genau ein Zeichen, und zwar ein nichtterminales Zeichen steht. |
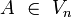 und
und 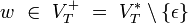 hat.
hat.
Eine Sprache heißt kontextfrei, wenn es eine kontextfreie Grammatik gibt, die diese Sprache erzeugt. In kontextfreien Grammatiken hängt die Anwendung einer Regel (A -> w) nicht von einer Umgebung von A ab.
Wir haben das leere Wort 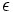 für w nicht zugelassen. Von dieser Ausnahme abgesehen, sind alle linkslinearen und abschließenden Regeln kontextfrei. Das bedeutet, dass alle linkslinearen Sprachen auch kontextfrei sind, wobei vom leeren Wort gegebenenfalls abzusehen ist.
für w nicht zugelassen. Von dieser Ausnahme abgesehen, sind alle linkslinearen und abschließenden Regeln kontextfrei. Das bedeutet, dass alle linkslinearen Sprachen auch kontextfrei sind, wobei vom leeren Wort gegebenenfalls abzusehen ist.
Im Artikel Allgemeine Regelsprachen haben wir einige Beispiele betrachtet. Die Grammatiken des Beispiels 1 und des Beispiels 5 sind kontextfrei, die der Beispiele 2, 3 und 4 nicht. Dies liegt daran, dass in diesen Beispielen Regeln vorhanden sind, die auf der linken Seite mehr als ein Zeichen enthalten, etwa die Regel (UT -> TU) in den Beispielen 2 und 3 und die Regel (Tb -> SUb) im Beispiel 4. Auch hier lässt sich aus der Art einer Grammatik noch nicht endgültig auf die Art der Sprache schließen. Zu den Beispielen 2 und 4 lässt sich nämlich jeweils eine kontextfreie Grammatik finden, die die gleiche Sprache erzeugt. Diese Sprachen sind also kontextfrei. Ohne Beweis sei angemerkt, dass die Sprache des Beispiels 3 nicht kontextfrei ist, obwohl die erzeugende Grammatik der des Beispiels 2 sehr ähnlich ist.
Die Beispiele zeigen, dass zumindest einfache Klammerstrukturen durch kontextfreie Sprachen beschrieben werden können.
Wir haben schon gesehen, dass es zu einer Sprache mehrere erzeugende Grammatiken gibt. Es gibt auch Grammatiken, in denen es mehrere Ableitungen zu einem Wort gibt. Sie heißen mehrdeutige Grammatiken. Wir betrachten dazu ein einfaches Beispiel:
Beispiel
Sei G = (VN, VT, P, S) gegeben mit
VN = {S}
VT = {a, b}
P = {S -> a | b | SS}
S =S
Das Wort w = abba kann von dieser Grammatik erzeugt werden.
Zu diesem Wort führen unter anderem die folgenden Ableitungen:
1. Ableitung:2. Ableitung:
3. Ableitung:
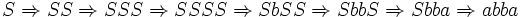
Solche Mehrdeutigkeiten sorgen dafür, dass die Analyse, ob Worte einer Sprache angehören, ineffizient sein kann. Dies ist für die Praxis nicht erfreulich. Die Frage der Ineffizienz wird später mit anderen Mitteln und an anderen Beispielen genauer untersucht.
Ohne Beweis vermerken wir, dass es von einer beliebigen kontextfreien Grammatik nicht entscheidbar ist, ob sie mehrdeutig ist.
Anweisungen - Syntaxanalyse von Pascal
Wir wenden unser bisheriges Wissen auf ein Problem der Syntaxanalyse von Pascal an. Wir betrachten dazu Anweisungen, allerdings in einer sehr eingeschränkten Form. Anweisungen seien nur nach folgendem Syntaxdiagramm zu bilden:
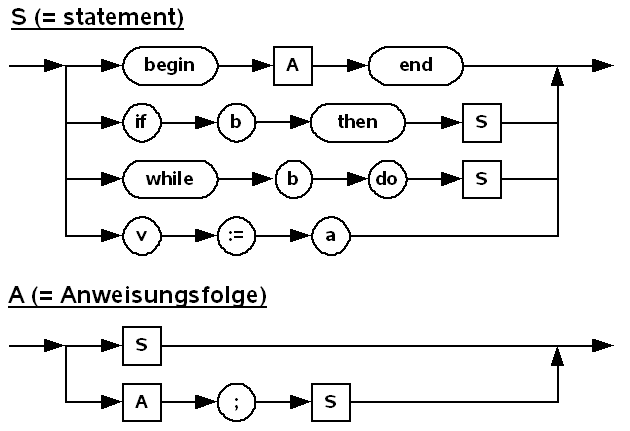
Weiter steht b für Bedingung, v für Variable und a für Ausdruck.
Die leere Anweisung entsprechend der Regel (S -> ) wurde weggelassen, weil dadurch der Bereich der kontextfreien Regeln verlassen würde.
Als Grammatik geschrieben erhalten wir folgende Form:
VN = {S, A}
VT = {a, b, begin, do, end, if then, while, v, ;, :=}
S = S
P = {(S -> begin A end | if b then S | while b do S | v := a),
(A -> S | A ; S)}
Wir wollen analysieren, ob das Wort
begin begin if b then v:= a; while b do begin v:= a end end end
eine Anweisung im Sinne unserer Syntax ist.
Wir führen die Analyse top down durch, d. h. wir versuchen aus dem Startsymbol S das Wort abzuleiten. Wir lesen jeweils links beginnend ein Zeichen des Wortes und führen die ersten Regeln aus, die nötig sind, um dieses Zeichen korrekt einzuordnen.
S -> begin A end -> begin S end -> begin begin A end end
Wir beginnen mit dem Startsymbol S. Wir lesen nun das erste Zeichen: begin. Es gibt nur eine Regel, in der begin auftritt, und diese ist auch anwendbar. Beim Lesen des zweiten begin gibt es keine Regel, die direkt anwendbar ist. Vielmehr müssen wir das A erst in ein S umwandeln. Dies ist mit zwei Regeln möglich. Wir haben willkürlich die erste benutzt. Weiter geht es mit:
... -> begin begin A end end
-> begin begin S end end
-> begin begin if b then S end end
-> begin begin if b then v:=a end end
Entsprechend fahren wir fort, wenn if zu bearbeiten ist. Wir ändern wieder willkürlich A in S um und haben dann eine anwendbare Regel. Das dann auftretende b then entspricht ganz dem bisher erzeugten Wort. Das v verlangt die Regel S -> v:=a, und diese kann angewandt werden. Dann taucht aber ein Strichpunkt ; auf, der nicht mehr passt. Bei der Ableitung müssen wir also einen Fehler begangen haben. Dies könnte an der letzten Stelle geschehen sein, bei der eine Auswahl zwischen mehreren Regeln möglich war. Wir gehen daher bis zu dieser Stelle zurück und versuchen, mit der anderen Regel die Ableitung zu beenden.
... -> begin begin A end end
-> begin begin A ; S end end
-> begin begin S ; S end end
-> begin begin if b then S ; S end end
-> begin begin if b then v:=a ; S end end
-> begin begin if b then v:=a ; while b do S end end
-> begin begin if b then v:=a ; while b do begin A end end end
-> begin begin if b then v:=a ; while b do begin S end end end
-> begin begin if b then v:=a ; while b do begin v:=a end end end
Wir haben bei unserem Ableitungsbaum Glück gehabt. Wir mussten nur einmal ein Ableitung ändern. Ein Backtracking Verfahren, wie hier angewendet, ist meist nicht effizient, denn in der Regel wächst sein Aufwand exponentiell mit der Länge des zu analysierenden Wortes.
Backtracking-Verfahren kann man manchmal vermeiden
- durch eine Änderung des Analyseverfahrens, teils top down, teils bottom up, oder
- durch eine Änderung der Syntax.
Der zweite Weg ist hier gangbar. Wir ersetzen die Regel (A -> A ; S) durch die Regel (A -> S ; A). Dadurch erhalten wir die gleiche Sprache (Beweis durch Induktion). Jetzt können wir die Analyse sackgassenfrei durchführen:
S -> begin A end -> begin S (;A)end -> begin begin A end end -> begin begin S (;A) end end -> begin begin if b then S (;A) end end -> begin begin if b then v:=a (;A) end end -> begin begin if b then v:=a ; S(;A) end end -> begin begin if b then v:=a ; while b do S (;A)end end -> begin begin if b then v:=a ; while b do begin A end end end -> begin begin if b then v:=a ; while b do begin S(;A)end end end -> begin begin if b then v:=a ; while b do begin v:=a end end end
Jetzt kann nämlich die Entscheidung, ob die Regel (A -> S) oder die Regel (A -> S ; A) angewendet wird, solange offengehalten werden, bis das erste Zeichen nach dem S, das Semikolon ";" oder das "end" kommt. Die Entscheidung wird also dadurch getroffen, dass man ein Zeichen vorausschaut (one symbol look ahead). Wir haben dies durch die Schreibweise S (; A) ausgedrückt, denn der Teil "; A" wird nur manchmal gebraucht.
Sprachen, die sich durch Vorausschau eines Zeichens sackgassenfrei top down analysieren lassen, heißen LL(1) Sprachen, allgemein LL(k) Sprachen, wenn man k Zeichen vorausschauen muss. Das erste L bedeutet dabei, dass das Wort von Links nach rechts abgearbeitet wird, das zweite L steht für eine Linksableitung, d. h. die Anwendung von Regeln beginnt ebenfalls links.
Hinweis: Es ist nicht entscheidbar, ob eine kontextfreie Sprache für ein beliebiges k, eine LL(k) Sprache ist.
Wir wollen unser Wort zur Übung in der ursprünglichen Grammatik auch bottom up analysieren, d. h. wir versuchen aus dem Wort den Startzustand abzuleiten. Wir beginnen wieder links und lesen Zeichen, und zwar so lange, bis wir eine Regel anwenden können. Die Regel wird angewendet, dazu eventuell weitere, dann wird wieder gelesen, bis die nächste Regel anwendbar ist. Dies wird fortgesetzt, bis das Startsymbol erreicht ist.
begin begin if b then v:=a <- Lesen -> begin begin if b then S -> begin begin S -> begin begin A -> begin begin A ; while b do begin v:=a <- Lesen -> begin begin A ; while b do begin S -> begin begin A ; while b do begin A -> begin begin A ; while b do begin A end <- Lesen -> begin begin A ; while b do S -> begin begin A ; S -> begin begin A -> begin begin A end <- Lesen -> begin S -> begin A -> begin A end <- Lesen -> S <- Startzeichen
Hier geht die Analyse sackgassenfrei. Auch hier kann man entscheiden, ob die Regel (A -> S) oder die Regel (A -> A ; S) anzuwenden ist, wenn man ein Zeichen vorausschaut. Eine solche Sprache heißt LR(1) Sprache, allgemein LR(k) Sprache, wenn man k Zeichen vorausschauen muss. Hierbei werden die Regeln von rechts angewandt.
Hinweis: Es ist nicht entscheidbar, ob eine kontextfreie Sprache für ein beliebiges k eine LR(k) Sprache ist.
Programme in Programmiersprachen, die LL(1) bzw. LR(1) Sprachen sind, lassen sich sehr rasch auf Fehler prüfen. Der Aufwand ist im Wesentlichen linear von der Programmlänge abhängig. Deshalb ist man bemüht, möglichst große Teile der Programmiersprachen entsprechend zu gestalten. Dieses war z. B. eines der wesentlichen Prinzipien bei der Gestaltung der Programmiersprache Pascal (siehe Niklaus Wirth; Compilerbau). Dies gilt insbesondere für den formalen Aufbau von arithmetischen Ausdrücken ohne Typprüfung und Wertebereichsprüfung und den von Anweisungen.
Die Programmiersprache FORTRAN ist dagegen anders gestaltet:
Bei den Strukturen DO 5 I = 1,9 (DO Schleife mit CONTINUE in Zeile 5) und DO 5 I = 1.9 (Wertzuweisung an „DO 5 I")
kann erst bei dem Komma bzw. Punkt erkannt werden, um welche Struktur es sich handelt.
Im Artikel Linkslineare Sprachen - reguläre Sprachen haben wir gesehen, dass die linkslinearen Sprachen sehr schöne Abschlusseigenschaften besitzen. Es sind nämlich Vereinigung, Durchschnitt und Komplement linkslinearer Sprachen ebenfalls wieder linkslinear.
Entsprechendes gilt für kontextfreie Sprachen nicht.
Die Vereinigung kontextfreier Sprachen ist kontextfrei. Es ist aber unentscheidbar, ob der Durchschnitt zweier bzw. das Komplement einer kontextfreien Sprache kontextfrei ist. Auch die Gleichheit zweier kontextfreier Sprachen ist unentscheidbar. Es ist auch nicht entscheidbar, ob eine kontextfreie Sprache linkslinear ist.
Die Sprachen 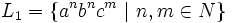 und
und  sind kontextfrei. Ihr Durchschnitt ist die Sprache
sind kontextfrei. Ihr Durchschnitt ist die Sprache 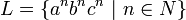 . Diese Sprache ist nicht kontextfrei. Dies werden wir später noch begründen.
. Diese Sprache ist nicht kontextfrei. Dies werden wir später noch begründen.