Programmiersprache für eine Turtle
Inhaltsverzeichnis
jar eingebunden
funktioniert wohl nicht mit dieser version ... such noch ...
Aufgabenstellung
Es soll ein Programm erstellt werden, das über eine Benutzeroberfläche gesteuert wird und - ähnlich wie die klassische Java-Turtle - zeichnen kann. Bei der Benutzung des Programms soll eine selbst erstellte Sprache zur Bedienung der Turtle zum Einsatz kommen.
Was wollen wir?
Aktionen
- Linien zeichnen
- sich drehen / die Zeichenrichtung ändern
- Farben ändern (Linie und Hintergrund)
- Position der Turtle ändern ohne zu zeichnen
- Figuren zeichnen
- Rechteck
- Kreis
- Vieleck
QuaderProblem: Darstellung der nicht sichtbaren Kanten
- Zeichnung löschen
Vereinbarungen
- Winkel, Längen und Koordinaten können nur mit positiven Zahlen angegeben werden.
- Das der Turtle zugrunde liegende Koordinatensystem hat seinen Ursprung O(0|0) in der linken unteren Ecke der Zeichenfläche.
- Der Winkel 0° liegt auf der rechten Hälfte der x-Achse.
- Winkel werden gegen den Uhrzeigersinn angetragen.
| Befehl | Definition |
|---|---|
| zeichne(x) | zeichne x Schritte |
| zeichnebis(x,y) | zeichne bis P(x;y) |
| drehe(α) | drehe um Winkel α |
| drehebis(α) | drehe auf Winkel α |
| springe(x) | gehe x Schritte, ohne Zeichnen |
| springebis(x,y) | gehe zu P(x;y), ohne Zeichnen |
| loesche() | Zeichnung löschen; Position, Winkel & Farben bleiben erhalten |
| nullen() | Zeichnung löschen; Position -> (0;0); α=0; Farben fg: schwarz; bg: weiß |
| zeichenfarbe(r,g,b) | einstellen der Zeichenfarbe |
| hintergrund(r,g,b) | einstellen der Hintergrundfarbe |
| rechteck(l,b) | zeichnet ein Rechteck von aktueller/m Position/Winkel aus mit Länge (1.) und Breite (2.) |
| rechteck(l) | zeichnet ein Quadrat von aktueller/m Position/Winkel aus mit Seitenlänge l. |
| kreis(r) | zeichnet einen Kreis mit aktueller Position als Mittelpunkt und Radius r. |
| vieleck(n,l) | zeichnet ein Vieleck mit n Ecken und Seitenlänge l |
| wiederhole(n)[B] | wiederholt den Befehl B n-mal |
Syntaxdiagramm
![]()
Programm:


Name:
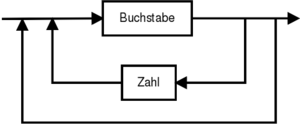
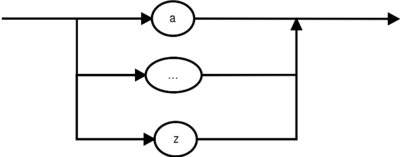
Buchstabe:
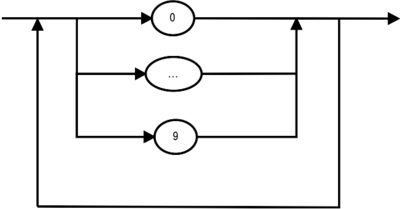
Zahl:
Gliederung des Gesamtproblems / Planung
Der Unterbau des Programms kann in drei Bestandteile zerlegt werden. Dieses sind die drei Automaten Scanner, Parser und Interpreter. Die in die Oberfläche eingegebenen Befehle durchlaufen die drei Automaten in der genannten Reihenfolge. Zuerst Durchläuft der Quelltext den Scanner. Dieser ist ein Transduktor, der den Quelltext auf das Nötigste reduziert. Beispielsweise werden Trennzeichen zwischen Befehlen weggelassen. Ein weiterer Teil der Quelltextreduzierung ist das Setzen von Tokens. Lange Befehle werden dabei durch ein einzelnes Zeichen ersetzt und die Parameter an das Zeichen angehängt. Fällt dem Scanner bereits ein Fehler auf, setzt er ein Fehlerzeichen. Ein Fehler könnte sein, dass ein Befehl falsch oder unbekannt ist. Der ausschließlich aus Tokens und zugehörigen Paramtern bestehende Text wird an den Parser weitergegeben, der ein Akzeptor ist. Er überprüft die Syntax des reduzierten Quellcodes. Dazu gehört die Prüfung, ob die für einen Befehl benötigten Parameter vorhanden sind. Außerdem bricht der Parser die Überprüfung sofort ab, wenn er auf ein vom Scanner gesetztes Fehlerzeichen stößt und meldet einen Fehler. Der syntaktisch richtige Text wird dann an den Interpreter übergeben. Der Interpreter führt diesen Text dann aus und man erhält die gewünschte Aktion aus dem Quelltext.

Scanner
Der Scanner ist ein Transduktor, der die eingegebenen Befehle vereinfacht. Er ersetzt alle ihm bekannten - also von uns definierten - Befehle durch die entsprechenden Tokens (quasi eine Abkürzung). Außerdem lässt er überflüssige Zeichen weg, wie z.B. die Endzeichen nach jedem Befehl oder Klammern an Anfang und Ende des Programms. Falls ein Fehler auftritt (unbekannter Befehl, unsinnige Zeichen) setzt er ein Fehlerzeichen.
Download: Media:Scanner.zip
Syntax
Trennzeichen zwischen Befehlen: ' )' Ursprünglich war das Semikolon als Trennzeichen vorgesehen. Da allerdings jeder Befehl mit ' )' endet, (siehe Vereinbarungen) haben wir beschlossen auf das Semikolon zu verzichten.
Tokens
| Befehl | Token | Befehl | Token |
|---|---|---|---|
| zeichne(x) | zx | zeichnebis(x,y) | Zx,y |
| drehe(α) | dα | drehebis(α) | Dα |
| springe(x) | sx | springebis(x,y) | Sx,y |
| loesche() | l | nullen() | n |
| zeichenfarbe(r,g,b) | fr,g,b | hintergrund(r,g,b) | hr,g,b |
| rechteck(l,b) | rl,b | rechteck(l) | rl |
| kreis(r) | kr | vieleck(n,l) | vn,l |
| wiederhole(n)[B] | wn(B) | ||
| Fehlerzeichen | # | Endzeichen | * |
Automat
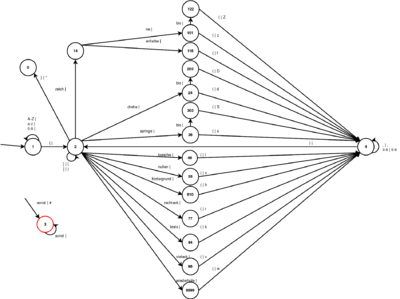
Der Automat beginnt in Zustand 1 (1. v.l., Mitte). Er erlaubt die Eingabe von Buchstaben und Zahlen, die den Namen des Programms darstellen. Während des Einlesens des Programmnamens findet keine Ausgabe statt. Erfolgt die Eingabe "{" wechselt der Automat in Zustand 2 (2. v.l., Mitte) und gibt wieder nichts aus.
Zustand 2 wechselt in einen der 10 Folgezustände, wenn der Anfangsbuchstabe eines definierten Befehls eingelesen wird. In der Darstellung rechts wurden einige Zustände aus Übersichtsgründen weggelassen. Ist z.B. als Eingabe "zeich" angegeben, bedeutet das, dass der Zustand erreicht wird über die nacheinander Eingabe von "z", "e", "i", "c" und "h" - jeweils ohne Ausgabe. Die Ausgabe des Tokens für den jeweiligen Befehl erfolgt erst, wenn "(" eingelesen wird, also der Beginn der Parameter. Damit wechselt der Automat in Zustand 4 (ganz rechts, Mitte). Da Parameter nur aus Zahlen bestehen können, erlaubt dieser Zustand die Eingabe von Zahlen und Kommas (zum Trennen mehrerer Parameter). Diese erlaubten Eingaben werden auch direkt wieder ausgegeben. Wird die Parameteraufzählung durch ")" abgeschlossen, wechselt der Automat wieder in Zustand 2 und kann einen neuen Befehl einlesen.
Tritt ein Fehler auf, d.h. eine unerlaubte Eingabe, so wechselt der Automat in Zustand 3 (rechts unten) und gibt "#" aus. Anders als in der Zeichnung aus Übersichtsgründen dargestellt, gehen von ihm die selben Verzweigungen ab, wie auch von Zustand 2. Der einzige Unterschied ist, dass bei weiteren fehlerhaften Eingaben kein "#" gesetzt wird. Das soll den Ausgabetext des Scanners übersichtlicher gestalten, da an einer Fehlerstelle nur eine Raute anstatt mehrerer erscheint (dies wird aber nicht immer funktionieren, Erläuterung weiter unten).
Wird in Zustand 2 "}" eingelesen (also das Programmende), so wechselt der Automat in Zustand 0 (links, oben) und gibt "*" aus. Folgt nach Ende dieser geschlossenen geschweiften Klammer noch Quelltext, gibt der Scanner nichts aus, da das Programm nach dieser Stelle beendet ist.
Nummerierung der Zustände
Auf den ersten Blick könnte die Zustandsnummerierung verwirrend erscheinen. Deshalb eine kurze Erläuterung der Gedanken:
Wir wollten im Code den Überblick behalten. Das wäre schwierig geworden, wenn wir die Zustände einfach aufwärts gezählt hätten. Wir wollten deshalb vor allem die Kettenstruktur im Nummerierungsschema abbilden. Deshalb bekommt eine Kette eine Anfangszahl zugeteilt. Am Beispiel der Kette, die mit "z" beginnt, wäre das die 1. In der zweiten Stelle der Zahl werden die Schritte innerhalb der Kette durchnummeriert. Nach z kommt also Zustand 10, beim "e" dann Zustand 11, bei "i" Zustand 12 usw.
Das funktioniert aber auch nur bis zu dem Punkt, an dem sich die Kette aufteilt in die zwei Stränge für "zeichne"/"zeichnebis" und "zeichenfarbe". An diesem Punkt werden die folgenden Zustände dreistellige Zahlen. Die Nummer der Kette (1) bleibt erhalten, eine Verzweigungszahl wird eingefügt, beginnend mit 0. Am Ende bzw. als dritte Ziffer werden wieder aufwärts die Schritte gezählt. Das wäre für "zeich" + "n" Zustand 100 und mit "e" dann 101. Für die zweite Verzweigung "zeichnebis" heißt der Zustand nach "b" dann 110 usw.
Ausgewählter Code
Überprüfung: Zahl / keine Zahl
private static boolean isNumber(char myChar) {
// Funktion überprüft, ob der eingegebene Character eine Zahl oder ein Komma ist
char[] z123 ={'0','1','2','3','4','5','6','7','8','9',','}; // Ein Feld mit allen erlaubten Zeichen (0-9, ',') wird erzeugt.
for(int i=0; i < z123.length; i++) { // Zählschleife für jede Stelle des Feldes.
if(z123[i] == myChar) { // Falls der Character einem Zeichen im Feld entspricht,
return true; // wird true zurückgegeben.
} else {}; // Ansonsten passiert vorerst nichts.
}
return false;
// Wurde mit der Schleife kein Zeichen im Feld gefunden, das dem Eingabezeichen entspricht, wird nun false ausgegeben.
}
Die Funktion zur Überprüfung, ob der eingegebene Character ein Buchstabe oder eine Zahl ist (isABC), funktioniert auf die gleiche Weise. Das Feld wird lediglich um die erlaubten Zeichen erweitert.
Zustand: Parameter
case 4: switch (e) {
//Zustand 4 wird erreicht, wenn als nächstes Parameter im Quelltext erwartet werden.
case ')' : {s=2; return s;}
//Eine ')' schließt die Aufzählung der Parameter ab. Deshalb könnte jetzt ein neuer Befehl beginnen.
default: if (isNumber(e) == true) { //Funktion isNumber(e) wird aufgerufen. Falls true,
s=4; //können weitere Zahlen oder Kommas zu den Parametern hinzugefügt werden.
return s; //Der aktuelle Zustand wird der Zustandsfunktion zurückgegeben.
}
}
Parser

Der Parser überprüft, ob der reduzierte Quelltext korrekt ist oder nicht.
Problem in der Darstellung als Automat:
Beim Parser muss beachtet werden, dass er aufgrund der Anweisung "wiederhole(Zahl)[Anweisung]", mit welcher man Anweisungen in einer Schleife wiederholen kann rekursiv arbeiten muss.
Dieses Problem kann in Java so gelöst werden, dass man die Anzahl der Klammern, die aufgehen und die,die zugehen, zählt. Die Anzahl der aufgehenden Klammern und zugehenden Klammern muss in einem korrekten Quelltext gleich sein. Im Automaten ist dies jedoch nicht darstellbar.
Hier wurde versucht anzudeuten mit Z0(0)und Z0(1), dass dieser Zustand praktisch derselbe ist. Alle Pfeile die aus Z0(0) herausgehen bzw. hereingehen und in einen anderen Zustand führen, müssten genauso auch aus Z0(1) herausführen bzw. hereinführen, nur eben in die entsprechenden Zustände mit Index 1. Der Index in Klammern zählt dann praktisch, wie oft man mit dem Wiederholenbefehl schon geschachtel hat. Dies kann theoretisch unendlich weit fortgeführt werden uns ist somit nicht besser im Automaten darstellbar.
Download: Media:Parser.zip
Interpreter
Bresenham-Algorithmus
Zur Umsetzung des Kreiszeichnens war es notwendig auf einen Algorithmus zurückzugreifen, da die Turtle nicht über eine eigene Kreis zeichnen Funktion verfügt.

Einer der Algorithmen mit denen man einen Kreis am Computer zeichnen lassen kann, ist eben der Bresenham-Algorithmus, der nicht nur spezifisch auf Kreise anwendbar ist, sondern auch etwas abgeändert auf Linien. Das Besondere an Bresenham ist, dass er Rundungsfehler vermindert und einfach zu implementieren ist, da der ganze Algorithmus keine Gleitkommazahlen beinhaltet, sondern mit ganzen Zahlen auskommt, und eigentlich keine komplexen Operationen vorkommen.
Kreisvariante des Algorithmus
Die Kreisvariante des Algorithmus geht nicht auf Bresenham selbst zurück, dennoch wurde sie aufgrund des verwandten Ansatzes nach ihm benannt.
Man geht bei dem Algorithmus grundsätzlich von der Kreisgleichung x² + y² = r² aus, um aber Wurzelberechnungen u.ä. zu vermeiden, wird der Term in Einzelschritte zerlegt und teilweise rekursiv berechnet.
Der Algorithmus berechnet dabei nicht einen ganzen Kreis, sondern lediglich einen Oktanten, da alle anderen Oktanten vom Prinzip her gleich aufgebaut sind und dann durch Spiegelung gezeichnet werden können.
Wer genaueres über die genaue Durchführung erfahren möchte, kann sich folgendes anschauliche Video auf Youtube anschauen:
Bresenham(Kreisvariante)-Videotutorial
Beispiele / Screenshots

Daten
Scanner Download: Media:Scanner.zip
Parser Download: Media:Parser.zip
Komplett Download Media:Turtle_Sprache_komplett.zip
Probleme / Lösungen
Die Trennung der Aufgaben von Scanner und Parser bedurfte des öfteren der Absprache. Es wäre an einigen Stellen einfach gewesen, Parser-Funktionen bereits in den Scanner zu integrieren. In den meisten Fällen haben wir die Aufgaben jedoch so aufgeteilt gelassen, wie es die Definition der beiden Automaten festschreibt.