Datenbankmodelle
Zur formalen Beschreibung aller in der Datenbank enthaltenen Daten und ihrer Beziehungen untereinander verwendet man auf der konzeptionellen und externen Ebene Datenmodelle. Hierbei stellt man Daten und Objekte, deren Eigenschaften (Attribute) und ihre Beziehungen untereinander auf. Diese Modelle sind unabhängig von der späteren konkreten Anwendung.
Inhaltsverzeichnis
Hierarchisches Datenbankmodell
Das hierarchische Datenbankmodell ist das älteste Datenbankmodell überhaupt. Es entstand aus dem Information Management System (IMS), welches zuvor von IBM entwickelt wurde.
Es besitzt prinzipiell eine satzorientierte Baumstruktur, welche aus 2 Elementen besteht: dem Record (Datensatz) und der Parent-Child-Relation ("Eltern-Kind-Beziehung", PCR). Ein Record, welcher der Vorgänger eines anderen Records ist, wird deshalb als "Parent" bezeichnet. Ein Record, welcher der Nachfolger eines anderen Records ist, wird als "Child" bezeichnet. Hat dieser Record keinen Nachfolger, so wird er als Blatt bezeichnet. Ein Parent kann mehrere Nachfolger haben, jedoch besitzt ein Child genau(!) einen Parent. Dies stellt im Wesentlichen die Problematik dieses Datenbankmodells dar: Zwischen zwei Records kann lediglich eine 1:1- bzw. eine 1:n-Beziehung bestehen. Die häufig benötigten n:m-Beziehungen sind mit diesem Datenbankmodell nicht möglich, weshalb es auch weitestgehend von anderen Modellen, wie dem Netzwerkdatenbankmodell oder dem Relationalen Datenbankmodell verdrängt wurde.
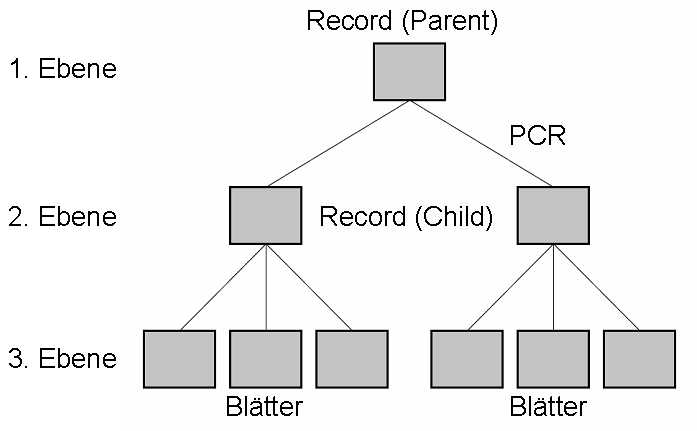
Heute wird das Hierarchische Datenbankmodell hauptsächlich bei Banken und Versicherungen eingesetzt, da es für große Datenbanken relativ gute Zugriffszeiten bietet.
Netzwerkdatenbankmodell
Das Netzwerkdatenbankmodell wurde 1971 von der Data Base Task Group (DBTG) der Conference on Data Systems Language (CODASYL), die sich allgemein mit der Entwicklung einer einheitlichen, systemunabhängigen Programmiersprache bechäftigt, vorgestellt. Es kann als "Verallgemeinerung" des Hierarchischen Datenbankmodells bezeichnet werden.
Die Records des Netzwerkdatenbankmodells bestehen aus Data Items (Feldern), die einen bestimmten record type (Satzart) bestizen. Diese Felder können jedoch auch Gruppenfelder sein und andere Felder enthalten. Mehrere Records desselben Typs heißen zusammengefasst record occurs (Wiederholungsgruppen). Die Beziehuungen zwischen den einzelnen Records wird durch sogenannte Datasets beschrieben. Jedes Dataset besitzt einen Owner, keinen, einen oder mehrere Member und einen Set-Type, welcher die eingentliche Art der Beziehung definiert.

Eine Umsetzung dieses Modells erfolgt häufig in der Programmiersprache COBOL, welche ebenfalls von der DBTG entwickelt wurde und daher eine gute Kompatiblität mit dem Modell bietet. Der Vorteil des Netzwerdatenbankmodells liegt in den guten Zugriffszeiten und es wird deshalb häufig auf Großrechnern eingesetzt, jedoch wird es immer mehr vom relationalen Datenbankmodell verdrgängt.
Relationales Datenbankmodell
Das relationale Datenbankmodell wurde von Edgar F. Codd in den 1960ern/70ern entwickelt und ist ein mengenorientiertes Datenbankmodell. Die Firma Oracle veröffentlichte wenige Jahre später die erste funktionierende Datenbank, die nach diesem System funktionierte.
Das Relationale Datenbankmodell stellt man sich allgemein als 2-dimensionale Tabelle vor. Es wird über Schlüssel definiert (Primärschlüssel) und verknüpft (Fremdschlüssel). Die Darstellung erfolgt sehr häufig im Entity-Relationship-Modell nach Chen.
Siehe dazu auch: Konzept des relationalen Datenbankmodells
Edgar F. Codd legte seinerzeit 12 Regeln fest, denen eine relationale Datenbank entsprechen sollte. (siehe Normalisierung)
Das relationale Datenbankmodell ist heute das am häufigsten verwendete Modell überhaupt, da es sich sehr einfach darstellen lässt. Der Nachteil dieses Modells liegt allerdings darin, dass unter Umständen durch eine große Anzahl an Tabellen Informationen weit verstreut sein können.
Objektorientiertes Datenbankmodell
Das objektorientierte Datenbankmodell ist eine relativ neue Entwicklung. Der Inhalt der Records sind Objekte im Sinne der OOP. Diese Objekte können auch Unterobjekte enthalten (siehe Vererbung in der OOP). Innerhalb der Objekte findet keine getrennte Speicherung von Methoden und Attributen statt. Dies bietet den Vorteil, dass eventuell benötigte Operatoren sofort in die Datensätze mit eingegliedert werden. Außerdem wird der Datenbank so mehr Semantik (logische Folge von Informationen) verliehen.
Dieses Modell konnte sich jedoch trotz guter Speicherzugriffe bis jetzt noch nicht am Markt etablieren.
Objektrelationales Datanbankmodell
Dieses Datenbankmodell stellt ein Bindeglied zwischen dem relationalen Datenbankmodell und dem objektorientierten Datenbankmodell dar. Es wird dann eingesetzt, wenn man Mengen von Objekten und der Beziehungen zu anderen Daten oder Objekten darstellen möchte.