Datenbanken mit Prolog
Inhaltsverzeichnis
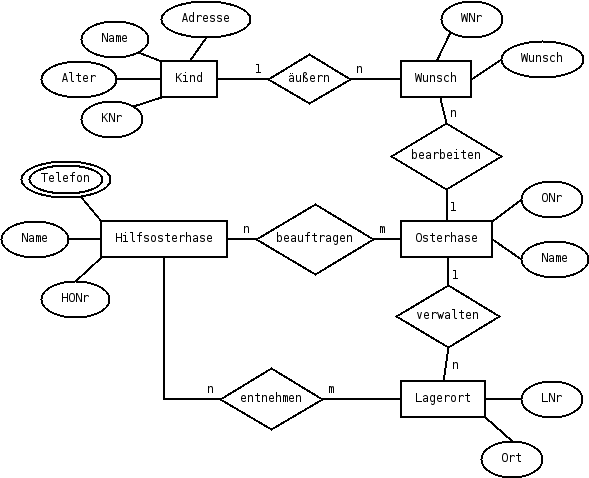
Darstellung anhand der Osterhasendatenbank
ER-Modell
Relationen-Modell
Aus dem ERM folgt die nachstehende Relationentabelle: (Primärschlüssel sind unterstrichen, Fremdschlüssel kursiv dargestellt)
Kind(KNr,Name,Alter,Adresse) Wunsch(WNr,Wunsch,KNr,ONr) Osterhase(ONr,Name) Lagerort(LNr,Ort,ONr) beauftragen(HONr,ONr) Hilfsosterhase(HONr,Name) Telefon(TNr,HONr) entnehmen(LNr,HONr)
Umsetzung in Prolog
%kind(KNr,Name,Alter,Adresse(Straße,Hausnr,Stadt)).
kind(1,alexander,8,adresse('Nirgendwostr.',37,'Fulda')).
[...]
Beachte: Großgeschriebenes wird durch Hochkommata gekennzeichnet, da es ansonsten als Variable und nicht als Konstante aufgefasst wird.
Außerdem wurde zur besseren Übersichtlichkeit beim Prädikat Adresse eine Schachtelung vorgenommen, sodass in Adresse die Elemente Straße, Hausnummer und Wohnort enthalten sind.
%osterhase(ONr,Name(Vorname,Nachname)).
osterhase(1,name('Ingo','Höpping')).
%lagerort(LNr,Ort,ONr).
lagerort(1,'EDV1',1).
[...]
%hilfsosterhase(HONr,Name).
hilfsosterhase(1,verena).
[...]
%beauftragen(ONr,HONr).
beauftragen(1,1).
[...]
%entnehmen(LNr,HONr).
entnehmen(3,1).
[...]
%wunsch(WNr,Wunsch,KNr,ONr).
wunsch(1,'Barbie',2,1).
[...]
%telefon(TNr,HONr)
telefon(066584327,1)
Anmerkung: Die komplette Wissensbasis findet sich zum Download am Ende der Seite.
Projektion
Die Projektion ![]() Attribut(Relation) zeigt einzelne Spalten (Attribute) einer Tabelle gemäß der Relationenalgebra.
Zur Projektion in Prolog wird hierbei die anonyme Variable _ verwendet, um Spalten auszublenden.
Attribut(Relation) zeigt einzelne Spalten (Attribute) einer Tabelle gemäß der Relationenalgebra.
Zur Projektion in Prolog wird hierbei die anonyme Variable _ verwendet, um Spalten auszublenden.
Hier bei der Osterhasendatenbank: Wo wohnen die Kinder?
Anfrage an Wissensbasis:
?- kind(_,Name,_,adresse(_,_,Ort)).
Ausgabe:
Name = alexander Ort = 'Fulda' ; Name = lukas Ort = 'Fulda' ; Name = florian Ort = 'Fulda' ; Name = niklas Ort = 'KiKa' ; Name = marcus Ort = 'Fulda' ; Name = harry Ort = 'Wolfsburg' ; Name = torben Ort = 'Fulda' ;
Selektion
Die Selektion ![]() Formel(Relation) gibt gemäß der Relationenalgebra Zeilen (Tupel) gemäß der Formel aus.
Zur Selektion in Prolog wird eine Variable (erster Buchstabe: Großbuchstabe) verwendet.
Beispiel: (hier zur besseren Übersichtlichkeit in Verbindung mit Projektionen)
Wie alt ist Torben?
Formel(Relation) gibt gemäß der Relationenalgebra Zeilen (Tupel) gemäß der Formel aus.
Zur Selektion in Prolog wird eine Variable (erster Buchstabe: Großbuchstabe) verwendet.
Beispiel: (hier zur besseren Übersichtlichkeit in Verbindung mit Projektionen)
Wie alt ist Torben?
Anfrage:
?- kind(_,torben,Alter,_).
Ausgabe:
Alter = 30
Join (Verknüpfung von Tabellen)
Der Join R ![]() S verknüpft zwei Tabellen über einem gemeinsamen Attribut.
In Prolog wird hierzu eine Anfrage gestellt, in der mehrere Relationen über eine gemeinsame Variable zusammengeführt werden.
Beispiel:
Was wünscht sich Alexander?
S verknüpft zwei Tabellen über einem gemeinsamen Attribut.
In Prolog wird hierzu eine Anfrage gestellt, in der mehrere Relationen über eine gemeinsame Variable zusammengeführt werden.
Beispiel:
Was wünscht sich Alexander?
Anfrage:
?- wunsch(_,Wunsch,Kindnummer,_), kind(Kindnummer,alexander,_,_).
Ausgabe:
Wunsch = 'Wunschlos glücklich' Kindnummer = 1
Erstellen eines Datensatzes
Beispiel für kunde(Knr, Status, Vorname, Nachname, Straße, Plz, Ort, Letzte_werbung, Zahlungsart):
kunde(100,‘S‘,‘Hans‘,‘Voss‘,‘Kuhdamm 12‘,23864,‘Nienwohld‘,‘2005-12-01‘,‘N‘).
Man beachte: Großgeschriebenes wird durch Hochkommas gekennzeichnet, da es ansonsten als Variable und nicht als Konstante aufgefasst wird.
Schachtelung von Prädikaten
Um eine bessere Struktur zu erhalten, werden z.B. die Prädikate name(Vorname, Nachname) und adresse(Straße, Nr., Plz, Ort) in das Prädikat kunde geschachtelt, so dass kunde dann so aussieht:
kunde(Knr,Status,name(Vorname,Nachname),adresse(Straße,Nr,Plz,Ort),Letzte_werbung,Zahlungsart).
Konkrete Fakten der Datenbasis würden dann folgendermaßen aussehen:
kunde(100,‘S‘,name(‘Hans‘,‘Voss‘),adresse(‘Kuhdamm‘,12,23864,‘Nienwohld‘),‘2005-12-01‘,‘N‘).
Projektion
Ein Unterstrich ‘_‘ ist eine sogenannte anonyme Variable, die bei Anfragen nicht mit Variablen gematcht wird.
Interessiert man sich z.B. nur für den Namen und den jeweiligen Wohnort eines Kunden, so wird in der Anfrage bei allem anderen '_' geschrieben:
?- kunde(_, _, Name, adresse(_, _, _, Wohnort), _, _).
Selektion
Sucht man einen Datensatz mit bestimmten Daten, wie z.B. Kunden aus Kayhude, dann werden die Daten in die Anfragen als Konstanten hineingeschrieben. Vorher genanntes Beispiel:
?- kunde(_, _, Name, adresse(_, _, _, 'Kayhude'), _, _).
Verknüpfen von Tabellen
Die Tabellen werden über beliebige Attribute gejoint, wobei die "verknüpfenden" Variablen in den verschiedenen Tabellen identisch geschrieben werden müssen.
So können z.B. alle Konten gesucht werden, bei denen der Kunde nicht gleichzeitig auch der Inhaber ist.
?- kunde(Knr, _, Name, _, _, _), girokonto(Knr, Inhaber, _, KontoNr), Name \== Inhaber.
Zusätzliche Regeln
Ist man permanent nur an bestimmten, sich oft ändernden Informationen interessiert, dann kann man eine neue Regel schreiben, welche die gewünschten Daten ausgeben kann. (Vergleichbar mit einem View in SQL)
kaufpreis(Bezeichnung,Preis):- artikel(_, Mwst, Bezeichnung, Listenpreis, _, _, _, _), mwstsatz(Mwst, Prozent, _), Preis is Listenpreis *(1+Prozent).
kaufpreis gibt also den Preis zzgl. Mehrwertsteuern jedes Artikels aus, ohne andere Daten anzuzeigen.
Diese neue Regel kann man wiederum in anderen Regeln verwenden.
bezahlbar(Bezeichnung,Betrag):- kaufpreis(Bezeichnung,Preis), Preis < Betrag.
Aggregatfunktionen
Zunächst muss man hierfür das Systemprädikat findall kennen:
findall(X, Anfrage, Ergebnisliste).
Findall sammelt alle Substitutionen von X in der Anfrage in einer Ergebnisliste.
Die Werte der Ergebnisliste können nun mit Hilfe der arithmetischen Listenoperationen ausgewertet werden, um die Summe, den Durchschnitt, das Minimum / Maximum, die Anzahl usw. der X-Werte herauszubekommen.
Anzahl:
count(X,Befehl, Ergebnis):-
findall(X,Befehl,L), anzahl(L,Ergebnis).
Beispiel: Die Anzahl der Kunden
?- count(X, kunde(X,_,_,_,_,_),Anzahl).
Minimum/ Maximum:
minimum(X,Befehl, Ergebnis):-
findall(X,Befehl,L), mini(L,Ergebnis).
maximum (X,Befehl, Ergebnis):-
findall(X,Befehl,L), maxi(L,Ergebnis).
Beispiel: Der teuerste/billigste Artikel
?- maximum(X, artikel(_,_,_,X,_,_,_,_), Ergebnis), artikel(_,_,Bezeichnung,Ergebnis,_,_,_,_). ?- minimum(X, artikel(_,_,_,X,_,_,_,_), Ergebnis), artikel(_,_,Bezeichnung,Ergebnis,_,_,_,_).
Summe:
sum(X,Befehl, Ergebnis):-
findall(X,Befehl,L), summe(L,Ergebnis).
Beispiel: Bestellmenge jedes Artikels
?- artikel(Artikel,_,Bezeichnung,_,_,_,_,_),sum(Bestellmenge, position(_,Artikel,Bestellmenge,_,_),Ergebnis).
Durchschnitt:
avg(X,Befehl, Ergebnis):-
findall(X,Befehl,L), durchschnitt(L,Ergebnis).
Beispiel: Wie viel Whisky wurde durchschnittlich bestellt?
avg_bestellmenge(Bezeichnung,Ergebnis):-
artikel(Artikel,_,Bezeichnung,_,_,_,_,_), avg(Bestellmenge,position(_,Artikel,Bestellmenge,_,_), Ergebnis). ?- avg_bestellmenge(’Whisky’, Y).