Reguläre Ausdrücke und reguläre Sprachen - Begriffsklärung
Wir haben bisher von Endlichen Automaten erkannte Sprachen kennen gelernt. In diesem Kapitel wollen wir Sprachen allgemeiner definieren und ein Beschreibungsmittel für Sprachen einführen, das es erlaubt, schrittweise alle Worte einer Sprache zu erzeugen. Solche mittels so genannter regulärer Ausdrücke beschreibbaren Sprachen sind genau die von Endlichen Automaten erkennbaren. Wir werden jedoch auch zeigen, dass es formale Sprachen gibt, die nicht von Endlichen Automaten erkannt werden können.
Wir können uns leicht überlegen, dass jede endliche Menge von Zeichenketten von einem Endlichen Automaten erkannt werden kann, denn wir brauchen nur einen Automaten zu entwerfen, der für jede dieser endlich vielen Zeichenketten einen Endzustand besitzt, in den der Automat auf genau eine Weise gelangen kann. Wir wollen uns nun fragen, wieso ein Automat, der nur endlich viele Zustände besitzt, in der Lage sein kann, unendlich viele korrekt gebildete Zeichenketten von unendlich vielen falsch gebildeten zu unterscheiden. Das ist nur dann möglich, wenn die Zeichenketten nach strengen Regeln aufgebaut sind, die es erlauben, sie durch einmaliges Lesen von links nach rechts zu analysieren, ohne jemals zurückschauen zu müssen. Diese Regeln werden wir in Form von regulären Ausdrücken beschreiben. Es sei X ein Alphabet, also eine endliche Menge von Zeichen, und X* die Menge aller Worte über diesem Alphabet, also die Menge aller endlichen Folgen von Zeichen aus X einschließlich des leeren Wortes 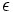 . Wir nennen dann jede Teilmenge
. Wir nennen dann jede Teilmenge 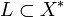 eine Sprache über dem Alphabet X. Wenn A ein endlicher Akzeptor ist, so bezeichnen wir die von ihm erkannte Sprache mit L(A).
eine Sprache über dem Alphabet X. Wenn A ein endlicher Akzeptor ist, so bezeichnen wir die von ihm erkannte Sprache mit L(A).
Für Sprachen über demselben Alphabet können wir gewisse Verknüpfungen definieren. Es seien 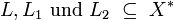 .
.
Die Konkatenation (das Produkt oder Aneinanderreihung) von L1 und L2, bezeichnet mit 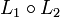 (oder kurz L1L2), ist die Menge aller Worte aus X*, für die eine Zerlegung in einen Wortanfang aus L1 und ein Wortende aus L2 möglich ist:
(oder kurz L1L2), ist die Menge aller Worte aus X*, für die eine Zerlegung in einen Wortanfang aus L1 und ein Wortende aus L2 möglich ist:
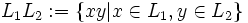
Die i-te Potenz von L für 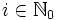 , bezeichnet mit Li, ist die Menge aller Worte aus X*, die aus i beliebigen Worten von L aneinandergereiht sind:
, bezeichnet mit Li, ist die Menge aller Worte aus X*, die aus i beliebigen Worten von L aneinandergereiht sind:
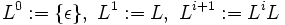
Die Iteration von L, bezeichnet mit L*, ist die Menge aller Worte aus X*, die durch endlich häufiges Aneinanderreihen von Worten aus L entsteht:
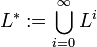
Für L=X ist also L* die Menge aller Worte über dem Alphabet X in Übereinstimmung mit der früheren Bezeichnung X*.
Beispiele
Es seien X= {a,b}, L1= {a,ab}, L2= {b,ba}. Dann ist
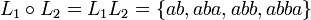 Hinweis: Die Konkatenation ist nicht kommutativ, d.h. ba oder auch bba gehören nicht zu L1L2
Hinweis: Die Konkatenation ist nicht kommutativ, d.h. ba oder auch bba gehören nicht zu L1L2
Es seien X= {a,b}, L1= {ab,b}, L2= {,a,aab,abb}, L= {a,bb}. Dann ist
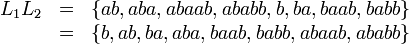
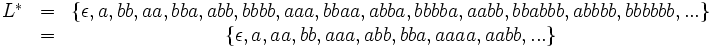
Die endliche Menge L1L2 ist durch die Aufzählung ihrer Elemente einfach zu beschreiben. Die unendliche Menge L* kann besser verbal beschrieben werden als die Menge aller Worte aus X*, bei denen die b paarweise auftreten, einschließlich des leeren Worts.
Wir führen deshalb ein neues Beschreibungsmittel für Wortmengen über einem Alphabet ein. Es wird uns erlauben, auch die Menge L* in einer einprägsamen Schreibweise anzugeben.