Look Ahead Parser
ACHTUNG SPOILER ... wer das liest, dem is am Montag während meinem Referat langweilig ;-)
Inhaltsverzeichnis
Bearbeitungsplan
- Aneignung der Theorie -check
- Aufstellen eines Konzeptes (agile methology) -check
- grobes Design aufstellen -check
- Schreiben des Hauptprogramms -check
- erkennen der First und Follow Mengen -check
- Ausgabe der First und Follow Mengen -check
- (Ausgabe einer Parsingtabelle) -check
- (Anwendung der Parsingtabelle in einem Parser)
- Refactoring -check
- Verfeinerung des Designs
- Erstellen der Präsentation -check
Problem

Beginnt ein Wort mit a wird die erste, sonst die zweite Alternative für S gewählt. Soll B abgeleitet werden, kann man auch immer am ersten Zeichen entscheiden, welche Produktion angewendet werden muss.
Das funktioniert bei der folgenden Grammatik nicht:

Wenn man einen Satz ableiten will, der mit ccc beginnt, kann man mit dem ersten c nicht entscheiden, ob ![]() angewendet werden soll.
angewendet werden soll.
Lösung des Problems : ein LookAhead Parser
LookAhead Parser
benötigt: kontextfreie Grammatik ohne Linksrekursion
Der LookAhead Parser erstellt First & Follow Mengen, mit deren Hilfe er eine LookAhead Menge / Parsingtabelle generiert. Mit dieser Tabelle können Grammatiken rekursivfrei geparst werden.
Umsetzung:

First Menge
Definintion:
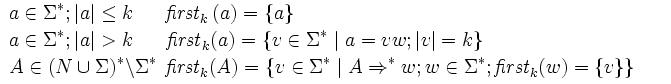
First(X) soll alle Terminale liefern, mit welchen X beginnen könnte.
Regeln für die Bestimmung der First Mengen:
Für alle Produktion werden folgende Regeln solange angewendet bis sich nichts mehr an den First Mengen ändert.

Beispiel:

Als erstes werden die First Mengen mit {} initialisiert
FIRST(E) = {}
FIRST(E') = {}
FIRST(T) = {}
FIRST(T') = {}
FIRST(F) = {}
Für T' → ε und E' → ε wenden wir die 2. Regel an.
FIRST(E) = {}
FIRST(E') = {ε}
FIRST(T) = {}
FIRST(T') = {ε}
FIRST(F) = {}
Wir benutzen Regel 3 für E' → +TE', hier fügen wir alles in First(+TE') bei First(E') ein.
Da First(+) Regel 1 benötigt fügen wir + in First(E') ein.
FIRST(E) = {}
FIRST(E') = {+,ε}
FIRST(T) = {}
FIRST(T') = {ε}
FIRST(F) = {}
Wir benutzen Regel 3 für T' → *FT', hier fügen wir alles in First(*FT') bei First(T') ein.
Da First(*) Regel 1 benötigt fügen wir * in First(T') ein.
FIRST(E) = {}
FIRST(E') = {+,ε}
FIRST(T) = {}
FIRST(T') = {*,ε}
FIRST(F) = {}
Zwei andere Produktionen beginnen mit Terminalen F → (E) und F → id, wenn wir hier auch die 3. Regel anwenden erhalten wir folgendes...
FIRST(E) = {}
FIRST(E') = {+,ε}
FIRST(T) = {}
FIRST(T') = {*,ε}
FIRST(F) = {'(',id}
Jetzt wenden wir die 3. Regel auch für T → FT' an, hier können wir First(FT') zu First(T)hinzufügen.
Da First(F) nicht ε erhält, ist First(FT') nur First(F)
FIRST(E) = {}
FIRST(E') = {+,ε}
FIRST(T) = {'(',id}
FIRST(T') = {*,ε}
FIRST(F) = {'(',id}
Nun wenden wir die 3. Regel auf E → TE' an, hier können wir First(TE') zu First(E) hinzufügen.
Da First(T) nicht ε enthält, ist First(TE') nur First(T).
FIRST(E) = {'(',id}
FIRST(E') = {+,ε}
FIRST(T) = {'(',id}
FIRST(T') = {*,ε}
FIRST(F) = {'(',id}
Da alles andere die Mengen nicht verändert sind wir fertig.
Umsetzung
/// <summary>
/// erstellt die Firstsets
/// </summary>
private void createFirstSets()
{
string tempString;
for (int i=0; i < (DGV_console.Rows.Count-1); i++)
{
tempString = Convert.ToString(DGV_console[0, i].Value);
// DGV_console[0,i] = Zeilen Tabelle in der die Produktion steht
first(tempString.Substring(0, (tempString.IndexOf('-'))).Trim(), tempString.Substring((tempString.IndexOf('>') + 1),
(tempString.Length - (tempString.IndexOf('-') + 2))).Trim());
//first(linke Seite der Produktion, rechte Seite der Produktion)
}
}
/// <summary>
/// hier werde die Firstmengen gebildet
/// und in ein Array firsets geschrieben
/// </summary>
/// <param name="nonterm"></param>
/// <param name="term"></param>
private void first(string nonterm, string term)
{
List<string> splittedterm = splitup(term);
string tempFirstsets;
bool containsEpsilon = true;
int xtemp = 0;
int splittedtermCount = splittedterm.Count - 1; // kommt immer ein Element mehr vor als wirklich drin is
if (terminals.isTerminal(splittedterm[0])) // wenn das erst Element terminal ist
{
firstsets[nonTerminals.getNonterminalIndex(nonterm)] = firstsets[nonTerminals.getNonterminalIndex(nonterm)] +
splittedterm[0];
}
else
{
bool epsilon = true;
int i = 0;
string tempFirst ="";
while (epsilon & (i < splittedtermCount))
{
if (nonTerminals.isNonterminal(splittedterm[i]))
{
tempFirst = firstsets[nonTerminals.getNonterminalIndex(splittedterm[i])];
if (tempFirst.IndexOf('ε') < 0)
{
firstsets[nonTerminals.getNonterminalIndex(nonterm)] =
firstsets[nonTerminals.getNonterminalIndex(nonterm)] + tempFirst;
epsilon = false;
}
else firstsets[nonTerminals.getNonterminalIndex(nonterm)] =
firstsets[nonTerminals.getNonterminalIndex(nonterm)] + tempFirst.Remove(tempFirst.IndexOf('ε'),1);
}
else
if(terminals.isTerminal(splittedterm[i]))
{
if (splittedterm[i] == "ε")
{
//nichts
}
else
{
firstsets[nonTerminals.getNonterminalIndex(nonterm)] =
firstsets[nonTerminals.getNonterminalIndex(nonterm)] + splittedterm[i];
epsilon = false;
}
}
i++;
}
if (epsilon & (i >= splittedtermCount))
firstsets[nonTerminals.getNonterminalIndex(nonterm)] = firstsets[nonTerminals.getNonterminalIndex(nonterm)] + 'ε';
}
}
Follow Menge
Für ein Nichterminal X liefert Follow(X) alle Terminale die direkt hinter X stehen können.
Regeln zur Bestimmung der Follow Mengen
Folgende Regeln werden auf alle Produktionen angwendet bis sich nichts mehr an den Follow Mengen ändert.

Beispiel
Die Mengen mit {} erstellen und $ bei S hinzufügen

Wir wenden Regel 2 auf F -> (E) an, hier wird First(')') zu Follow(E) hinzugefügt.

Wir wenden Regel 3 auf E -> TE' an, hier wir alles aus Follow(E) zu Follow(E') hinzugefügt.
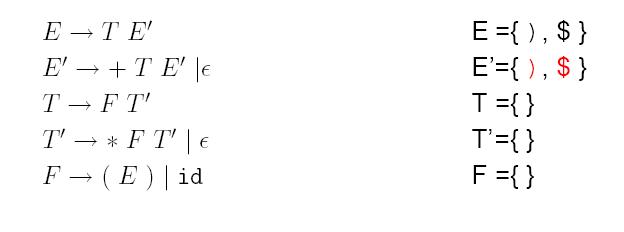
Da First(E') ε enthalten kann, wird Follow(E) bei Follow(T) hinzugefügt
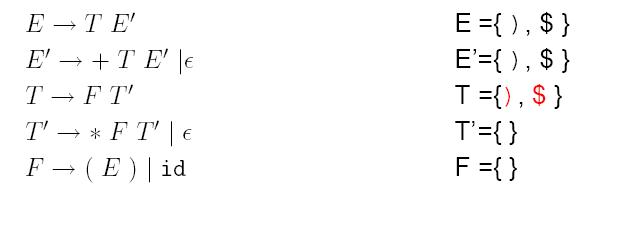
Da E' auf T folgt wird First(E')\ ε bei Follow(T) hinzugefügt.

Die Produktion T -> FT' endet mit T', deswegen fügt, wegen Regel 3, Follow(T) bei Follow(T') hinzu.

Bei der Produktion T' -> *FT' kann First(T') ε werden, deswegen wird Follow(F) Follow(T') hinzugefügt.

Da bei der Produktion T -> FT' - T' auf F folgt - wird First(T')\ε
zu Follow(F) hinzugefügt.

Umsetzung
private void createFollowsets()
{
string tempString;
followsets[nonTerminals.getNonterminalIndex(TB_start.Text)] = "$";
for (int i = 0; i < (DGV_console.Rows.Count - 1); i++)
{
tempString = Convert.ToString(DGV_console[0, i].Value);
follow(tempString.Substring(0, (tempString.IndexOf('-'))).Trim(), tempString.Substring((tempString.IndexOf('>') + 1),
(tempString.Length - (tempString.IndexOf('-') + 2))).Trim());
}
}
private void follow(string nonterm, string term)
{
List<string> splittedTerm = splitup(term);
for (int i = 0; i < (splittedTerm.Count -1); i++)
{
if (nonTerminals.isNonterminal(splittedTerm[i]))
{
if ((i + 1) < splittedTerm.Count -1)
{
if (terminals.isTerminal(splittedTerm[(i + 1)]))
{
followsets[nonTerminals.getNonterminalIndex(splittedTerm[i])] =
followsets[nonTerminals.getNonterminalIndex(splittedTerm[i])] + splittedTerm[(i + 1)];
}
if (nonTerminals.isNonterminal(splittedTerm[(i + 1)]))
{
int x = (i + 1);
bool epsilon = true;
while ((x < (splittedTerm.Count - 1))& epsilon)
{
if (nonTerminals.isNonterminal(splittedTerm[x]))
{
string tempFirst = firstsets[nonTerminals.getNonterminalIndex(splittedTerm[x])];
if (tempFirst.IndexOf('ε') < 0)
{
followsets[nonTerminals.getNonterminalIndex(splittedTerm[i])] = followsets[nonTerminals.getNonterminalIndex(splittedTerm[i])] + tempFirst;
epsilon = false;
}
else
{
followsets[nonTerminals.getNonterminalIndex(splittedTerm[i])] =
followsets[nonTerminals.getNonterminalIndex(splittedTerm[i])] + tempFirst.Remove(tempFirst.IndexOf('ε'),1) +
followsets[nonTerminals.getNonterminalIndex(nonterm)];
}
}
if (terminals.isTerminal(splittedTerm[x]))
{
followsets[nonTerminals.getNonterminalIndex(splittedTerm[i])] = followsets[nonTerminals.getNonterminalIndex(splittedTerm[i])] + splittedTerm[x];
}
x++;
}
}
}
if (i == (splittedTerm.Count-2))
{
followsets[nonTerminals.getNonterminalIndex(splittedTerm[i])] =
followsets[nonTerminals.getNonterminalIndex(splittedTerm[i])] + followsets[nonTerminals.getNonterminalIndex(nonterm)];
}
}
}
}
LookAhead Menge / Parsingtabelle
Erläuterung

Beispiel
M[v,t] wird mit {} initialisiert

Da ε nicht in First(T) enthalten ist, gilt Regel 4.1.
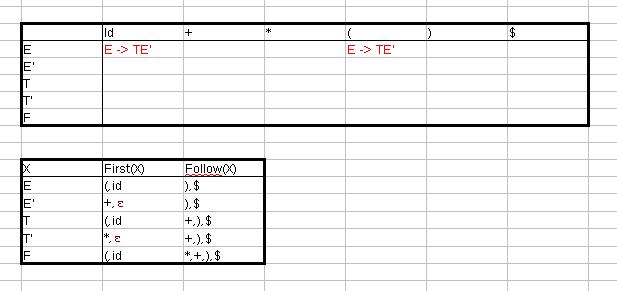
Weil ε nicht in First(+) enthalten ist, gilt Regel 4.1.
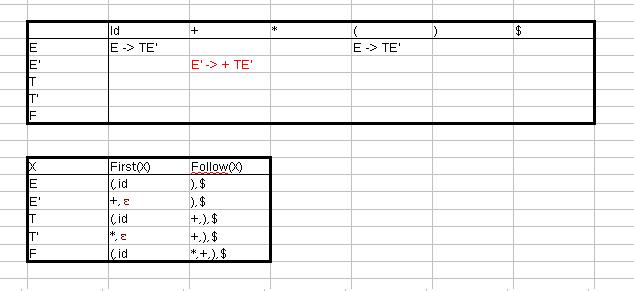
Da First(ε) ε enthält, wird die Produktion zu allen Elementen der Follow Mengen hinzugefügt.
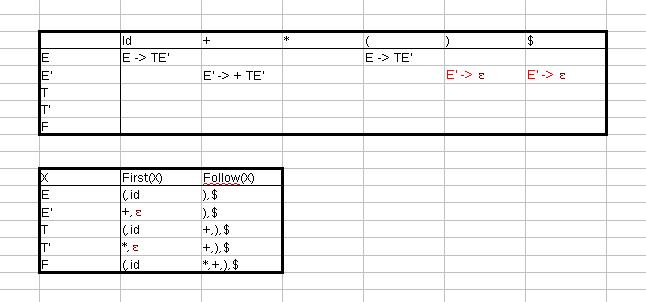
Da First(F) nicht ε enthält, gilt Regel 4.1.
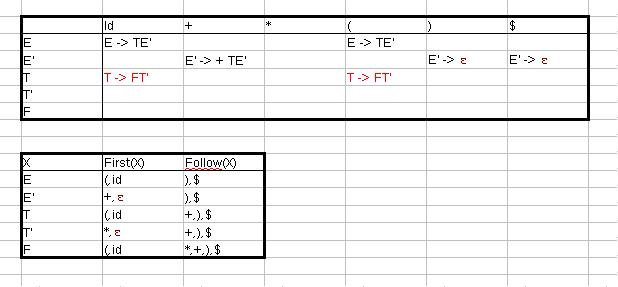
Da First(*) nicht ε enthält, gilt Regel 4.1.
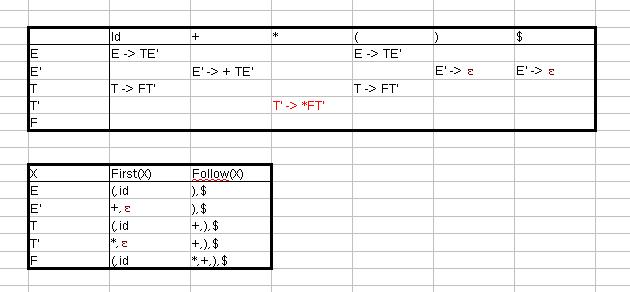
Da First(ε) ε enthält, wird die Produktion zu allen Elementen der Follow Mengen hinzugefügt.
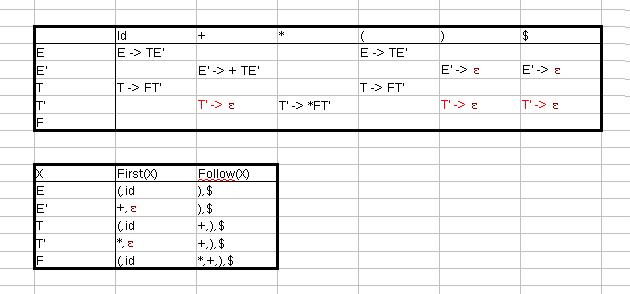
Da First('(') nicht ε enthält, gilt Regel 4.1.
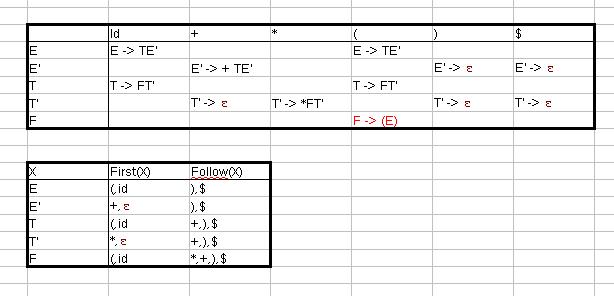
Da First(id) nicht ε enthält, gilt Regel 4.1.
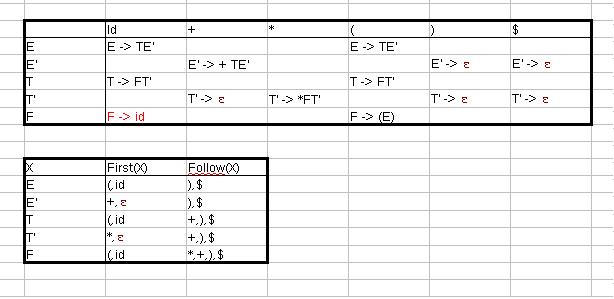

Wenn es jetzt keine Mehrfacheinträge gibt, kann man für jede Kombination von Symbolen entscheiden, welche Produktion angewendet werden soll.
---> Ausgangsproblem gelöst!
Umsetzung
private void createLASets()
{
string leftside = "";
List<string> rightside;
string temprightside = "";
List<string> splittedFirst;
List<string> splittedFollow;
for (int i = 0; i < (DGV_console.Rows.Count -1); i++)
{
leftside = DGV_console[0,i].Value.ToString().Substring(0,DGV_console[0,i].Value.ToString().IndexOf('-')).Trim();
temprightside = DGV_console[0, i].Value.ToString().Substring((DGV_console[0, i].Value.ToString().IndexOf('>') +
1)).Trim();
rightside = splitup(temprightside);
if (terminals.isTerminal(rightside[0]))
{
if (!(rightside[0] == "ε"))
DGV_laSets[(terminals.getTerminalIndex(rightside[0])+1), nonTerminals.getNonterminalIndex(leftside)].Value = DGV_console[0, i].Value;
else
{
splittedFollow = splitup(followsets[nonTerminals.getNonterminalIndex(leftside)]);
for (int y = 0; y < (splittedFollow.Count - 1); y++)
{
if (!(splittedFollow[y] == "$"))
{
DGV_laSets[(terminals.getTerminalIndex(splittedFollow[y])+1),
nonTerminals.getNonterminalIndex(leftside)].Value = DGV_console[0, i].Value;
}
else
{
DGV_laSets[((DGV_laSets.Columns.Count-1)), nonTerminals.getNonterminalIndex(leftside)].Value =
DGV_console[0, i].Value;
}
}
}
}
else
{
splittedFirst = splitup(firstsets[nonTerminals.getNonterminalIndex(rightside[0])]);
for(int x = 0; x < (splittedFirst.Count-1) ; x++)
{
if(splittedFirst[x] == "ε")
{
splittedFollow = splitup(followsets[nonTerminals.getNonterminalIndex(leftside)]);
for (int y = 0; y < (splittedFollow.Count - 1); y++)
{
if (!(splittedFollow[y] == "$"))
{
DGV_laSets[(terminals.getTerminalIndex(splittedFollow[y])+1),
nonTerminals.getNonterminalIndex(leftside)].Value = DGV_console[0, i].Value;
}
}
}
else
{
DGV_laSets[(terminals.getTerminalIndex(splittedFirst[x])+1),
nonTerminals.getNonterminalIndex(leftside)].Value = DGV_console[0, i].Value;
}
}
}
}
}
Quellen
http://users.informatik.haw-hamburg.de/~voeller/fc/comp/node16.html
http://www.cs.uiuc.edu/class/fa05/cs421/current/lectures/oldlectures/15-firstfollow.pdf
http://en.wikipedia.org/wiki/LL_parser
http://www.jambe.co.nz/UNI/FirstAndFollowSets.html
http://en.wikipedia.org/wiki/Lookahead
http://de.wikipedia.org/wiki/LL(k)-Grammatik
http://olli.informatik.uni-oldenburg.de/lalr/tutorial/deutsch/flow5/page1.html
http://casablanca.informatik.hu-berlin.de/database/pi3-ws2006/VL/II.3.Parser.PI-3(11).pdf
http://casablanca.informatik.hu-berlin.de/database/pi3-ws2004/VL/CB-Parser-4.pdf
Projektende: 18.01.06